| Lesson 4 | Databases and Web sites |
| Objective | Explain the characteristics and protocols of back-end Web databases. |
Back-End Web Databases: Characteristics and Protocols
A back-end Web database is the data layer that supports a dynamic Web application. It stores business facts, user records, product details, orders, permissions, content, logs, and operational state so that a website or application can display information, accept updates, process transactions, and respond to user requests in a controlled way. When a site allows a customer to search a catalog, sign in, update a profile, place an order, publish an article, or review an account history, a back-end database is usually involved.
This lesson is about more than naming a few database products. The real goal is to understand what makes a Web database useful in production and how it communicates with the rest of the stack. In older systems, that stack often consisted of a browser, a Web server, a server-side script, and a relational database sitting behind the scenes. In modern systems, the same logical flow may involve a browser or mobile app, an API gateway, application services, an ORM, one or more managed databases, background jobs, object storage, and observability tooling. The architecture has evolved, but the essential question remains the same: how does a Web application move data safely and efficiently between users, software, and storage?
Back-end Web databases appear in many forms. A small business may use a managed PostgreSQL database as part of a rapid deployment stack. A startup might choose Supabase to combine Postgres, authentication, storage, and edge functions. A product team may select PlanetScale when it wants MySQL-compatible workflows with branching and operational separation. A content-heavy system may use a headless CMS such as Contentful or Sanity alongside a commerce engine and customer database. A flexible document workload may rely on MongoDB Atlas. The technologies vary, but the characteristics of effective back-end databases are remarkably consistent.
What Makes a Website Database-Driven?
A database-driven website is characterized by three broad capabilities:
- It can display data retrieved from a database.
- It can accept criteria or input from a user or application and use that input to query or update stored data.
- It can store new or changed data in a structured and controlled way.
These capabilities sound simple, but they support a wide range of modern behavior. Searching for products, filtering by color or size, personalizing content, managing a customer account, checking inventory, generating a dashboard, or publishing a new article all depend on these underlying database interactions. A Web database therefore does not merely “sit behind” a site. It actively supports the site’s core operations.
Characteristics of Back-End Web Databases
1. Structured Persistence
The first characteristic of a back-end Web database is persistence. Data must survive after a page request finishes, a browser tab closes, or an application server restarts. Customer profiles, content entries, order histories, subscriptions, and audit records cannot disappear when the current session ends.
Persistence also implies structure. In a relational system, that structure usually appears as tables, keys, constraints, and indexes. In a document database, it appears as well-defined collections and documents, often with flexible schemas. In both cases, the database provides a durable representation of business reality.
2. Query Capability
A Web database must support selective retrieval. Users rarely want all the data. They want the right data. A site visitor might want “all shoes in size 9,” an editor might want “draft articles awaiting review,” and an administrator might want “orders placed today that failed payment authorization.” The ability to search, filter, sort, join, group, and paginate data is central to database usefulness.
In relational systems, SQL remains the dominant query language. In modern platforms, however, query execution may be wrapped by application code, API layers, SDKs, or ORMs rather than written directly into page templates.
3. Transaction Reliability
A serious Web application must preserve correctness during change. If a customer completes checkout, the system may need to reserve inventory, write an order, record a payment state, and initiate downstream fulfillment. Those operations must not leave the system in a contradictory state.
For that reason, back-end databases often support transactional guarantees. In relational systems, this is usually described through ACID properties: atomicity, consistency, isolation, and durability. For many business workloads, especially commerce, finance, healthcare, and internal systems of record, transaction reliability is one of the most important database characteristics.
4. Concurrency Control
Web systems are multi-user environments. Multiple shoppers may browse the same catalog, multiple administrators may edit records, and multiple services may read or update related data at the same time. A back-end database must therefore manage concurrent access without corrupting results.
This is where concurrency control matters. Some systems use locks; others rely heavily on multi-version concurrency control. The goal is to let users and services work in parallel while preserving accuracy and consistency.
5. Security
Back-end Web databases routinely store sensitive information: user identities, internal content, customer behavior, order data, vendor data, and sometimes regulated information. Security therefore includes authentication, authorization, encryption, secrets handling, access policies, auditing, and network restrictions.
In modern platforms, security may be reinforced by managed services, role-based controls, row-level security, TLS-encrypted connections, private networking, and identity-aware application logic. Security is not a decorative feature. It is a core database characteristic.
6. Integrity and Validation
A database must help preserve valid information. Primary keys, foreign keys, unique constraints, check constraints, and controlled mutation patterns help keep data consistent across time. Application code can perform validation, but the database remains the last defensive boundary before the data is written permanently.
This is especially important when multiple services or applications interact with the same data store. Without integrity rules, one system may write values that another system cannot trust.
7. Performance and Scalability
Back-end Web databases must respond quickly enough to support the application experience. Slow queries lead to slow pages, delayed dashboards, sluggish APIs, and poor operational feedback. Performance depends on good schema design, indexes, workload fit, caching strategy, query shape, connection handling, and infrastructure choices.
Scalability matters as traffic and data volume grow. A small internal site may run well on a single managed database instance. A larger platform may need read replicas, partitioning, sharding, background workers, caching layers, or region-aware deployment.
8. Backup, Recovery, and Operational Resilience
A production database must survive mistakes and failures. Recovery planning covers backups, point-in-time restore, replication, failover, and operational discipline. For regulated systems, resilience is also tied to governance and retention requirements.
This characteristic is often underestimated during development but becomes essential as soon as the application holds valuable business data.
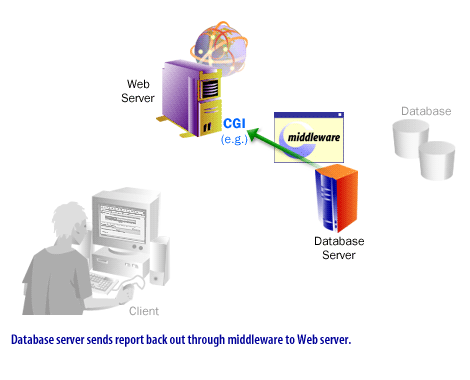
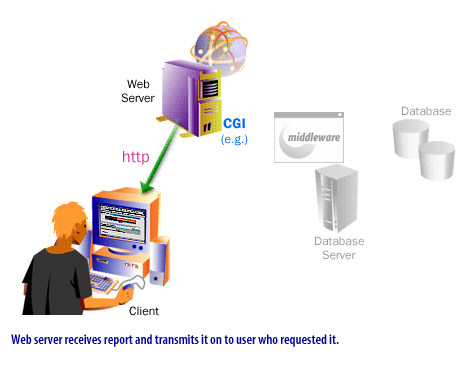
How Back-End Web Databases Communicate
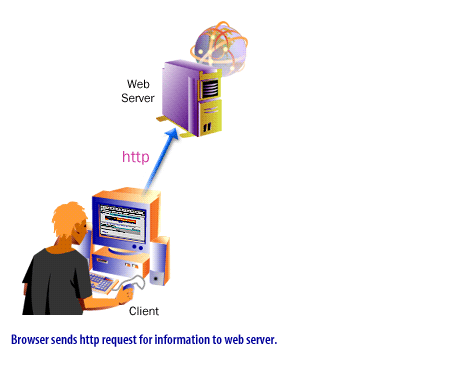
The legacy lesson correctly emphasized that a user does not usually connect directly from a browser to a database server. The browser talks to a Web-facing application layer, and that application layer talks to the database. This architectural separation is still the norm because it improves security, maintainability, and control.
The communication path can be described as a sequence:
- The user interacts with a browser, app, or other client.
- The client sends an HTTP or HTTPS request to a Web server, application server, edge runtime, or API endpoint.
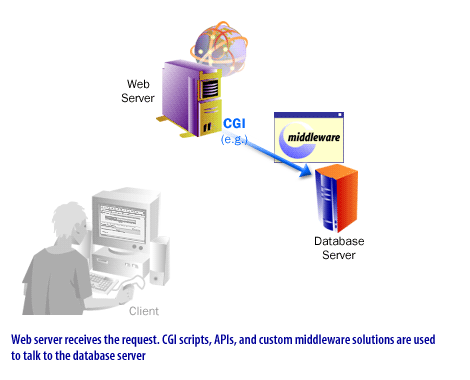
- The application layer interprets the request, validates input, checks identity and permissions, and determines what data operation is needed.
- The application uses a database access method such as an ORM, native driver, JDBC, ODBC, or platform SDK to communicate with the database engine.
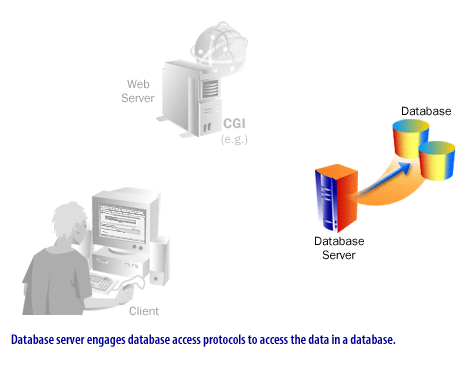
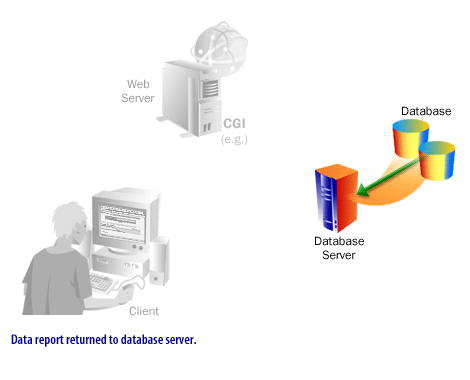
- The database executes queries or transactions and returns results.
- The application formats the result as HTML, JSON, GraphQL response data, or another payload.
- The response is sent back to the client over HTTP or HTTPS.
This point is important: browsers usually speak Web protocols, while applications and services speak database interfaces to the database engine. Mixing these categories leads to confusion.
Protocols and Interfaces in the Stack
HTTP and HTTPS
HTTP and HTTPS are the primary protocols used between the browser or client and the Web-facing application. HTTPS adds transport encryption, making it suitable for authenticated sessions, commerce, administrative functions, and sensitive interactions.
In modern architectures, even server-to-server API calls often use HTTP-based interfaces. That is common in microservices, headless commerce, and composable systems.
REST and GraphQL APIs
Most modern Web applications do not expose databases directly to browsers. Instead, they expose controlled APIs. REST remains common for resource-oriented services, while GraphQL is common where clients need flexible shapes of data. In headless commerce and headless CMS architectures, APIs are often the primary boundary between the front end and the back end.
This pattern is especially important when the same data must support websites, mobile apps, kiosks, internal tools, and third-party integrations.
SQL and Database Query Languages
SQL is still the dominant language for relational database access. It is used directly or indirectly in platforms based on PostgreSQL, MySQL, and compatible engines. Non-relational systems often expose their own query models, aggregation frameworks, or platform-specific access patterns.
Even when developers work through an ORM, the underlying database still executes the necessary read and write operations according to its own engine behavior.
JDBC and ODBC
JDBC and ODBC are best understood as database access interfaces, drivers, or APIs rather than browser-level Web protocols. JDBC is the standard Java approach for connecting applications to relational databases. ODBC is a widely used database API abstraction with broad vendor support.
They remain relevant in enterprise integration, reporting tools, legacy interoperability, and some application stacks, but they sit behind the application tier rather than in the browser-to-site communication path.
TCP/IP and TLS
At the network layer, database connections generally run over TCP/IP. In production, those connections are commonly protected with TLS so that credentials and query traffic are encrypted in transit. This is especially important for cloud-hosted databases, cross-network communication, regulated workloads, and zero-trust operational models.
Legacy Patterns versus Modern Patterns
Legacy Web-database stacks often relied on CGI scripts, direct SQL embedded in server pages, ADO, OLE DB, and tightly bundled monolithic deployments. Those systems were historically important because they made early dynamic sites possible, but they were often harder to scale, secure, and evolve.
Modern alternatives usually separate concerns more clearly. Application logic may run in server frameworks, containerized services, or edge/serverless functions. Data access may be mediated through ORMs such as Prisma, platform SDKs, or carefully structured service layers. Deployment may occur through Docker containers and Kubernetes orchestration. Infrastructure may be defined with Terraform or Pulumi rather than manual server-by-server setup.
This shift does not eliminate the database. It places the database inside a better-defined operational architecture.
Modern Platforms and Architectural Examples
Managed Relational Platforms
Managed PostgreSQL and MySQL-compatible platforms are attractive when teams want dependable relational behavior without carrying all the operational burden themselves. These platforms often provide backups, access controls, observability features, and operational automation that would otherwise require significant in-house expertise.
Supabase and Rapid Product Delivery
Supabase is useful as an example of a modern back-end platform because it combines a Postgres database with adjacent capabilities such as authentication, storage, realtime features, and edge functions. For small teams or prototypes, this reduces the friction of assembling multiple services by hand.
PlanetScale and Controlled Schema Workflows
PlanetScale illustrates another modern trend: operationally safer schema workflows and cloud-managed scale. The broader lesson is that database development now often includes branching, migration discipline, rollout controls, and production-aware change management.
MongoDB Atlas and Flexible Document Workloads
MongoDB Atlas is representative of managed document-database platforms. It is often useful when the application benefits from a flexible document model, rapid iteration, or workloads that do not map cleanly to rigid relational schemas.
Headless Commerce and Headless CMS
In composable commerce, the storefront, content system, search layer, and transaction systems are often decoupled. Shopify Storefront API is a good example of a commerce-facing interface for custom storefronts. Contentful and Sanity illustrate the headless CMS pattern, where editorial content is managed centrally and delivered via APIs to multiple channels.
In these architectures, databases remain crucial, but the front end often consumes data through APIs instead of rendering directly from a monolithic server page.
Business Scenarios
Small Business Sites
A small business often needs rapid deployment, reasonable cost, and minimal operational overhead. A managed relational database paired with a hosted application stack or platform service may be the right fit. Here the most important characteristics are reliability, basic reporting, security, easy backups, and enough flexibility to support growth.
Enterprise Systems
Enterprise environments usually need stronger workflow control, integration with other systems, more sophisticated reporting, stronger governance, and clearer separation between public and internal operations. In these settings, back-end databases often support APIs, internal dashboards, batch jobs, partner integrations, and audit trails simultaneously.
Regulated Industries
Healthcare, finance, insurance, and government systems place special emphasis on transport security, controlled access, auditability, retention, backup, recovery, and policy enforcement. In such environments, protocol selection and network design are not merely technical details. They are part of operational trust and compliance.
Interpreting the Image Sequence
The image series on this page still teaches a valid core lesson: the user initiates a request, the Web-facing tier receives it, application logic interprets it, the data tier is consulted, and the result flows back to the requester.
What should be modernized is the terminology. Instead of describing the middle layer primarily in terms of CGI scripts, it is more accurate today to describe it as an application layer composed of server-side frameworks, APIs, middleware, serverless functions, edge runtimes, or containerized services. Instead of implying that ODBC or JDBC are the main “Web protocols,” it is more accurate to say that they are database access interfaces used by the application tier.
Conclusion
Back-end Web databases are defined by their ability to store, retrieve, update, protect, and organize application data in support of dynamic websites and Web applications. Their most important characteristics include persistence, query capability, transaction reliability, concurrency control, integrity, security, scalability, and recoverability.
Their communication model also follows a clear pattern: clients talk to Web-facing systems over HTTP or HTTPS, the application tier enforces logic and access control, and the application uses database interfaces and drivers to talk to the database engine over secured network connections. In older architectures this might have been a monolithic server script and direct database call. In modern architectures it may be an API service, ORM, managed platform, containerized workload, or serverless function. The principles remain, but the tooling has matured.
Understanding these characteristics and protocols helps you design systems that are not only dynamic, but also maintainable, secure, and appropriate for the needs of small businesses, enterprise platforms, and regulated environments alike.