| Lesson 3 | Database Models |
| Objective | Describe the four basic database models and explain how each has evolved into modern data platform equivalents. |
Database Models (Hierarchical, Relational, Network, and Object)
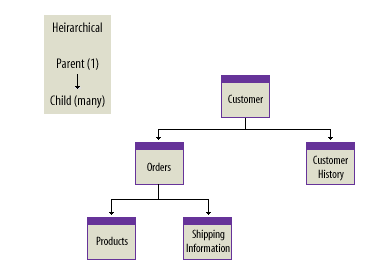
1) Hierarchical Database
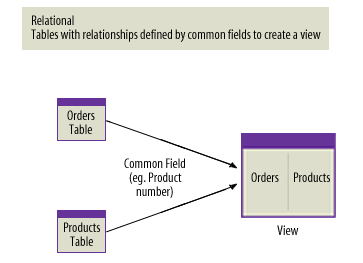
2) Relational Database
- The relational model's power lies in its mathematical foundation. Set theory and predicate logic underpin Structured Query Language (SQL), which allows any relationship between tables to be expressed as a query without requiring advance knowledge of how the data will be accessed. The query "return the full name and email address of every customer who placed an order in the last 30 days for a product in the electronics category" can be answered by joining four tables — customers, orders, order_items, products — using a SQL SELECT statement, without any of those tables having been designed with that specific question in mind.
- The relational model has dominated database design since the 1980s and remains the foundation of the most widely deployed database systems in production today. PostgreSQL, the open-source relational database, has become the default choice for new web applications due to its ACID transaction guarantees, JSON support for semi-structured data, full-text search capabilities, and a rich extension ecosystem. MySQL powers WordPress and the majority of PHP-based web applications. SQL Server remains the standard in Microsoft-centric enterprise environments.
Modern managed cloud services — AWS RDS, Google Cloud SQL, Supabase, PlanetScale — provide PostgreSQL or MySQL as fully managed platforms that handle replication, automated backups, scaling, and patching without requiring database administration expertise. Supabase combines PostgreSQL with a real-time API layer, authentication, and object storage, providing a complete backend platform built on open standards. PlanetScale, built on Vitess (the MySQL scaling technology that powers YouTube), adds horizontal sharding and schema change workflows that eliminate migration downtime.
ORMs (Object-Relational Mappers) bridge the relational model and application code by generating type-safe SQL from application-layer objects. Prisma (TypeScript/Node.js), SQLAlchemy (Python), Hibernate (Java), and Eloquent (PHP/Laravel) allow developers to interact with relational databases through the programming language's native data structures rather than writing raw SQL for routine operations. Migration tools — Flyway, Liquibase, and framework-native systems like Django migrations — manage schema evolution through version-controlled files that can be applied, reviewed, and rolled back like application code.
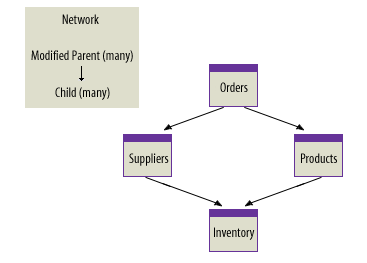
3) Network Database
- The network model was formalized by the CODASYL (Conference on Data Systems Languages) committee in the late 1960s and implemented in systems like IDMS (Integrated Database Management System). It addressed the hierarchical model's relationship limitations while retaining its performance characteristics for known access paths. The trade-off was complexity: network databases required developers to navigate explicit pointers between records, making queries dependent on knowledge of the physical data structure.
- The network model's graph approach to data relationships anticipated modern graph databases by several decades. Neo4j, the leading graph database platform, stores data as nodes and relationships (edges) and excels at queries that traverse complex relationship networks: fraud detection (following transaction chains to identify suspicious patterns), recommendation engines (finding products purchased by customers similar to the current user), and knowledge graphs (mapping relationships between concepts, entities, and facts). Social networks — where users follow other users who follow other users — represent a natural graph structure that the relational model handles awkwardly but graph databases handle natively.
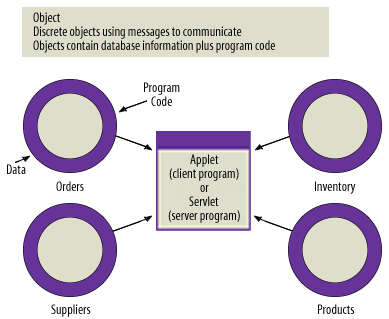
4) Object Database
- An object database stores a Customer object with its associated methods (calculateLoyaltyPoints(), getOrderHistory()) intact, rather than decomposing that object into normalized relational tables that must be reconstructed on retrieval. This makes object databases well-suited for domains where the data model is complex, deeply nested, and tightly coupled to application behavior: engineering CAD systems, scientific simulation data, multimedia asset management.
- Object databases are language-agnostic — they are not tied to Java or any specific language, though object-oriented languages (Java, C++, Python, C#) map naturally to the object storage model. db4o and ObjectStore were prominent object database systems; Realm (now MongoDB Realm) provides an object database for mobile applications.
- The object database's influence is most visible in modern document databases. MongoDB stores data as BSON documents (Binary JSON) that map directly to the objects used in application code — a MongoDB document can contain nested arrays and embedded sub-documents that mirror complex object graphs without the normalization that relational schemas require. Firestore, Google's managed document database, provides real-time synchronization of document collections, making it well-suited for collaborative applications and mobile backends where data must stay synchronized across multiple clients.
Choosing a Database Model for Modern Web Projects
The four foundational models map onto the contemporary database landscape in ways that make the historical survey practically useful for modern development decisions. Relational databases (PostgreSQL, MySQL) remain the correct choice when data integrity, complex querying, and ACID transaction guarantees are required — financial systems, order management, user account data, content management. The relational model's mathematical rigor and SQL's expressive power have proven durable across five decades and are unlikely to be displaced for structured data workloads. Document databases (MongoDB Atlas, Firestore) — the descendants of the object model — are appropriate when data structures are heterogeneous, schema evolution is rapid, or the application data maps naturally to JSON documents: product catalogs with varying attribute sets, user-generated content, mobile application backends.
Graph databases (Neo4j, Amazon Neptune) — the descendants of the network model — are appropriate when relationship traversal is the primary query pattern: fraud detection, recommendation engines, access control systems, knowledge graphs. Hierarchical structures persist in specialized contexts: LDAP directories, XML configuration systems, and file system representations where tree-based organization aligns with the domain. Most production web applications use a combination: a relational database for transactional data, a document or key-value store (Redis) for caching and session management, and potentially a search engine (Elasticsearch, Typesense) for full-text search. The database selection decision is not a single choice but a set of choices aligned with the specific data requirements of each subsystem.