| Lesson 6 | Understanding Internet Protocols |
| Objective | Describe the Nature of Protocols on the WWW |
Describe the Nature of Internet Protocols on the Web
When people browse a website, stream media, submit a form, sign in to an application, or call an API, they are relying on a layered system of communication rules known as protocols. On the World Wide Web, protocols define how data is packaged, addressed, transmitted, secured, acknowledged, and interpreted between systems. Without shared rules, a browser would not know how to request a page, a server would not know how to answer, and intermediary devices would not know how to route traffic across the Internet.
In general terms, a protocol is a formal specification that tells participating systems how to communicate. It describes message format, sequencing, error handling, expected responses, and sometimes security behavior. Protocols are not unique to the Web, but the Web depends on them heavily because it operates across many vendors, operating systems, devices, cloud platforms, and network providers. A Windows laptop, an iPhone, a Linux server, a CDN edge node, and a managed database can all cooperate because they implement common Internet standards.
The early Web was often explained as a simple exchange between one client and one server. That explanation still has educational value, but the modern Web is more complex. Today a single page load may involve DNS resolution, TLS negotiation, HTTP requests, CDN caching, image optimization, JavaScript bundles, API calls, third-party analytics, identity providers, and background service traffic. Even so, the same foundational idea remains true: communication works because both sides follow agreed-upon protocol rules.
Protocols on the Web are usually best understood as part of a layered architecture. At the application layer, protocols such as HTTP, WebSocket, and email-related protocols define the meaning of requests and responses. At the transport layer, TCP or UDP governs how data moves between endpoints. At the network layer, IP handles addressing and routing so packets can traverse many networks. At the security layer, TLS protects data in transit. These layers work together rather than competing with one another.
Open Standards and Vendor-Specific Protocols
Protocols can be broadly divided into open standards and vendor-specific or proprietary approaches. Open standards are published specifications that can be implemented by many vendors. This openness is one reason the Web became globally scalable. Protocols such as HTTP, HTTPS, TCP, UDP, IP, DNS, and TLS are not limited to a single platform. They are supported across browsers, servers, operating systems, routers, and cloud services.
Vendor-specific networking technologies historically played a larger role on private networks. For example, technologies such as AppleTalk or certain legacy Windows networking stacks reflected specific ecosystem needs. Over time, however, organizations standardized on TCP/IP-based networking because it provided interoperability across hardware and software boundaries. In practice, modern Apple, Microsoft, Linux, Android, and cloud environments all depend primarily on IP networking and higher-level open protocols layered on top of it.
This shift matters because the Web is inherently heterogeneous. A public-facing site cannot assume that all users share the same operating system, browser engine, access network, or device class. Open protocols make the Web resilient, portable, and vendor-neutral. They also enable modern development workflows in which front-end applications, reverse proxies, load balancers, object storage, observability pipelines, and SaaS integrations must all communicate predictably.
The Nature of Protocols: Connectionless and Connection-Oriented Communication
One classic way to classify protocols is by whether they are connectionless or connection-oriented. This distinction is most meaningful at the transport layer.
A connectionless transport does not establish a persistent session with guaranteed delivery semantics before sending data. The most common example is UDP (User Datagram Protocol). UDP sends datagrams with minimal overhead. It does not guarantee delivery, ordering, or retransmission by itself. That makes UDP useful when low latency matters more than perfect reliability, or when the application layer is prepared to handle loss or reordering on its own. DNS queries, some real-time media flows, and modern QUIC-based traffic all use UDP as a transport foundation.
A connection-oriented transport establishes a session and manages sequencing, retransmission, and delivery guarantees. The classic example is TCP (Transmission Control Protocol). TCP performs a handshake, tracks byte order, retransmits lost segments, and presents a reliable ordered stream to the application. For many years, most Web traffic relied on HTTP running over TCP, usually secured with TLS. This model remains important and is still widely used for HTTP/1.1 and HTTP/2 deployments.
It is important to describe this carefully: TCP is connection-oriented, while IP is the addressing and routing layer beneath it. The term TCP/IP refers to the protocol suite, not to a single protocol with one behavior. In older instructional material, TCP/IP was sometimes discussed as though it were one protocol. In modern technical writing, it is more accurate to separate the roles of TCP and IP and then explain how the broader Internet protocol suite supports the Web.
How Modern Web Traffic Actually Works
When a user enters a URL, several protocols may participate before any visible content appears. First, the browser often consults DNS to translate a domain name into an IP address. After that, the browser opens a transport path using TCP or a UDP-based mechanism such as QUIC, depending on the protocol stack in use. If the site is secure, which modern public sites should be, the client and server negotiate TLS so that the session is encrypted and authenticated. Only then does the browser send an HTTP request for the resource.
The server processes the request and returns an HTTP response containing status information, headers, and a representation of the requested resource such as HTML, JSON, CSS, JavaScript, an image, or another media type. The browser then interprets the response and may issue many additional requests for linked assets. In a modern application, some of those requests go not only to the origin server but also to a CDN, an image service, an API gateway, a payment endpoint, an identity platform, or a telemetry service.
This reveals an important principle: protocols are not merely about “sending files.” They coordinate meaning across distributed systems. HTTP communicates request methods, resource locations, cache directives, content types, authentication headers, redirects, and status codes. TLS establishes confidentiality and server identity. IP enables routing. Transport protocols control delivery behavior. Each protocol handles a different concern.
From Older Web Models to Contemporary Protocol Design
Older introductory lessons often emphasized protocols such as HTTP and FTP side by side. That made sense historically, but modern Web practice is different. FTP has largely disappeared from public-facing web architecture because it lacks the security and operational fit expected in contemporary environments. File transfer workflows today are more commonly handled through HTTPS-based uploads, secure APIs, managed object storage, SFTP in administrative contexts, or CI/CD deployment pipelines.
Similarly, older network planning often referenced T1 and T3 leased lines as standard business connectivity. Those technologies were once important, but modern organizations more often use fiber, cable, carrier Ethernet, 5G failover, SD-WAN overlays, and direct connectivity into cloud platforms. The lesson for protocol design is that the Web stack must operate across diverse and changing access networks. Good protocol design therefore favors interoperability, congestion awareness, security, and efficient recovery from packet loss.
Another major change is that the secure Web has become the default. It is no longer best practice to discuss HTTP in isolation from security. In production environments, HTTPS should be treated as the norm, which means HTTP layered over TLS. This protects credentials, session tokens, personal data, and business transactions from eavesdropping or tampering while data is moving across networks.
Connection Reuse, Persistence, and the Limits of the Older Model
The older explanation that “connectionless means the client and server disconnect after data is transmitted” is directionally useful for beginners, but the modern Web benefits from a more precise description. In practice, connection behavior depends on the protocol stack, protocol version, and implementation details. For example, HTTP/1.1 introduced persistent connections so multiple requests could reuse the same TCP connection. HTTP/2 improved efficiency further through multiplexing. HTTP/3 runs over QUIC, which itself uses UDP, showing that a UDP-based transport can still support sophisticated, stateful, reliable communication semantics at higher layers. In other words, modern protocol behavior cannot be understood fully from transport labels alone.
This is why protocol analysis should distinguish between transport properties and application semantics. UDP is connectionless as a transport, but QUIC builds richer connection management, encryption, stream multiplexing, and recovery behavior on top of UDP. TCP is connection-oriented, but the application using it still defines what the messages mean and when the conversation is complete.
The Protocol Sequence Illustrated
The following image sequence still provides a useful conceptual introduction to request-and-response behavior between a client and a server. It should be interpreted as a simplified teaching model rather than as a complete representation of modern browser networking.

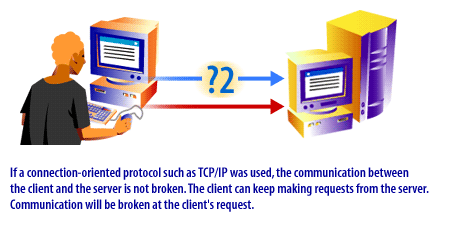
In current web architecture, this sequence would typically be accompanied by DNS lookups, TLS negotiation, caching logic, and possibly CDN or API gateway participation. Even so, the diagrams remain useful because they introduce the central idea that communication occurs in an ordered series of steps rather than as random data transfer.
Why Protocols Matter to Modern Web Development
For developers, designers, administrators, and digital strategists, protocol knowledge is practical rather than theoretical. Understanding protocols helps explain why secure sites require certificates, why some applications perform better under HTTP/2 or HTTP/3, why API calls may fail across network boundaries, why cookies and headers behave the way they do, and why observability tools measure latency across several layers. It also helps teams make better architecture decisions when selecting CDNs, reverse proxies, cloud load balancers, identity services, headless CMS platforms, or edge security providers.
A modern digital presence depends on protocol-aware design. Fast websites benefit from compression, caching, efficient connection reuse, and modern transport behavior. Secure websites depend on TLS and sound certificate management. Distributed applications depend on stable API contracts and predictable HTTP semantics. Real-time experiences may require WebSocket or other low-latency communication models. Protocol literacy therefore supports performance, security, interoperability, and maintainability.
Conclusion
The nature of protocols on the World Wide Web is best understood as a system of shared communication rules operating across multiple layers. Protocols specify how devices discover one another, how messages are formatted, how requests and responses are exchanged, how data is routed, and how communication is protected. Some protocols are connectionless, some are connection-oriented, and modern web systems often combine both approaches within one overall transaction flow.
Although older examples focused on a simple browser-to-server conversation, the contemporary Web is more distributed, more secure, and more performance-sensitive. Yet the core lesson has not changed: the Web functions because clients, servers, intermediaries, and services agree to follow common protocols. Mastering those protocols is essential for understanding how modern websites, applications, APIs, and cloud-connected services actually work.