URL Parts
Question: What are the parts of a Uniform Resource Locator?
A Uniform Resource Locator (URL) is a standardized way of specifying the location of a resource on the Internet. A URL consists of several parts, each of which provides specific information about the location and type of resource being accessed. Here are the parts of a typical URL:
In summary, a URL is composed of several parts, each of which provides information about the location and type of resource being accessed. Understanding the parts of a URL is essential for navigating the Internet and accessing online resources.
A Uniform Resource Locator (URL) is a standardized way of specifying the location of a resource on the Internet. A URL consists of several parts, each of which provides specific information about the location and type of resource being accessed. Here are the parts of a typical URL:
- Scheme: The scheme indicates the protocol used to access the resource. Examples of schemes include "http://" for Hypertext Transfer Protocol (HTTP), "ftp://" for File Transfer Protocol (FTP), and "https://" for HTTP Secure.
- Host: The host part of the URL specifies the domain name or IP address of the server hosting the resource. For example, in the URL "http://www.example.com/index.html", "www.example.com" is the host.
- Port: The port number is an optional part of the URL that specifies the network port on the server where the resource is located. If no port number is specified, the default port for the scheme is used. For example, the default port for HTTP is 80, while the default port for HTTPS is 443.
- Path: The path part of the URL specifies the location of the resource on the server's file system. It is typically a hierarchical path separated by forward slashes ("/"). For example, in the URL "http://www.example.com/dir1/dir2/file.html", "/dir1/dir2/file.html" is the path.
- Query string: The query string is an optional part of the URL that contains additional parameters for the server to use when processing the request. It is typically separated from the path by a question mark ("?") and consists of a series of key-value pairs separated by ampersands ("&"). For example, in the URL "http://www.example.com/search?q=example", "?q=example" is the query string.
- Fragment: The fragment part of the URL specifies a specific section of the resource to be displayed. It is typically separated from the rest of the URL by a hash sign ("#"). For example, in the URL "http://www.example.com/page.html#section3", "#section3" is the fragment.
In summary, a URL is composed of several parts, each of which provides information about the location and type of resource being accessed. Understanding the parts of a URL is essential for navigating the Internet and accessing online resources.
Parts of aURL
With Hypertext and HTTP, URL is one of the key concepts of the Web. It is the mechanism used by browsers to retrieve any published resource on the web. URL stands for Uniform Resource Locator and is nothing more than the address of a given unique resource on the Web. In theory, each valid URL points to a unique resource. Such resources can be an HTML page, a CSS document, an image, etc. In practice, there are some exceptions, the most common being a URL pointing to a resource that no longer exists or that has moved.
As the resource represented by the URL and the URL itself are handled by the Web server, it is up to the owner of the web server to carefully manage that resource and its associated URL.
As the resource represented by the URL and the URL itself are handled by the Web server, it is up to the owner of the web server to carefully manage that resource and its associated URL.
Uniform Resource Locator Definition
So how does your favorite browser navigate this tangled network of computers to find just the web page you want? It’s all in what is known as the URL (Uniform Resource Locator), which is simply the website address you type into your browser, like www.seotrance.com
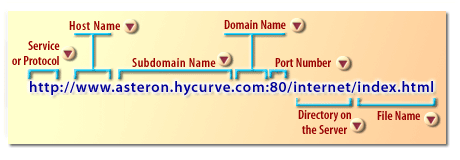
- The service or protocol part of the URL identifies the types of internet service the browser uses to access the resources
- The host name is used to identify web resources on HTTP servers. Host names are optional.
- The subdomain name identifies the name of the server hosting the resources
- The Domain name identifies the type of entity providing the resource.
- The Port number designates the specific TCP/IP port being used to process the request and will default to 80 if it is omitted.
- The Directory identifies the location of the resources on the host server.
- The file name identifies the name of the resource
URL Defined
Uniform Resource Locator - Protocol Description
URL is the syntax and semantics for a compact string representation of a resource available via the Internet. For example, we use URL to locate web addresses and FTP site addresses. The generic syntax for URLs provides a framework for new schemes to be established using protocols other than those defined in this document. URLs are used to 'locate' resources, by providing an abstract identification of the resource location. Having located a resource, a system may perform a variety of operations on the resource, as might be characterized by such words as "access", "update", "replace", "find attributes". In general, only the "access" method needs to be specified for any URL scheme.